How to create a land cover model for South America in 4 steps
Recently, Radiant Earth Foundation released a land cover dataset for South America, continuing the work they had been doing in other parts of the world and in connection with other areas of interest.
In connection with previous posts, this article explains how to train a segmentation model based on this dataset in just 4 steps. Specifically, we will explain in detail how to train a model for classifying the use of cropland, based on the mentioned dataset.
The dataset: LandCoverNet South America
The released dataset comprises labels and satellite imagery from Sentinel-1, Sentinel-2 and Landsat 8 missions for classifying the uses of South American land (if you would like to learn more about satellite imagery sources, click here).
Each pixel is identified as one of the possible seven land classes: water, natural bare ground, artificial bare ground, woody vegetation, cultivated ground, semi-cultivated ground, and permanent snow/ice.
The first version of LandCoverNet South America includes a total of 1,200 image chips of 256 x 256 pixels spanning 40 tiles. Each image chip contains temporal observations from the following satellite products with an annual classification label, all stored in raster format (GeoTIFF files):
- Sentinel-1: GDR detection (ground range distance) with radiometric calibration and orthorectification at 10m spatial resolution.
- Sentinel-2: surface reflectance product (L2A) at 10m spatial resolution.
- Landsat-8: surface reflectance product from Collection 2 Level-2.
LandCoverNet has many advantages, including its CC-BY-4.0 license, which allows users to apply and modify its content without major restrictions. To learn more about this development from Radiant Earth, you can click here*.
How to train a model for classifying the use of cropland
Before starting, it is strongly recommended to execute this code in an environment which enables access to a GPU. At the end of this guideline, there is a link to access the notebook in Google Colaboratory format.
Steps:
1- Downloading the dataset
2- Preprocessing of sentinel-2 imagery
3- Preprocessing of annotations
4- Model training
1- Downloading the dataset
To complete this step, we recommend you to check the guideline posted by Radiant Earth. It explains how to register as a user and how to create an API.
import osos.environ[‘MLHUB_API_KEY’] = <API KEY>
In this guideline, we will work with Sentinel-2 imagery and the annotations. In particular, we will download bands linked to Blue, Green and Red (2, 3 and 4). To speed up the process, we will take into account just a hundred cases (instead of the 1,200 available). To obtain data related with the license, the citation and the description, we execute the following:
collection_id = ‘ref_landcovernet_sa_v1_source_sentinel_2’collection = client.get_collection(collection_id)print(f’Description: {collection[“description”]}’)print(f’License: {collection[“license”]}’)print(f’DOI: {collection[“sci:doi”]}’)print(f’Citation: {collection[“sci:citation”]}’)Description: LandCoverNet South America Sentinel 2 Source ImageryLicense: CC-BY-4.0DOI: doi.org/10.34911/rdnt.6a27yvCitation: Radiant Earth Foundation (2022) “LandCoverNet South America: A Geographically Diverse Land Cover Classification Training Dataset”, Version 1.0, Radiant MLHub. https://doi.org/10.34911/rdnt.6a27yv
To download them, we will use a set of features exemplified in the documentation. We did not include them in this post for the sake of brevity, but you can find them in the final notebook and in the official documentation. We execute the following:
items = get_items(collection_id,max_items=100,)for item in items:download_labels_and_source(item, assets=[‘B02’, ‘B03’, ‘B04’])
The downloaded chips are stored by default in the data directory.
For the annotations in particular, we need to download the source file (zipped) directly.
collection_id = 'ref_landcovernet_sa_v1_labels'collection = client.get_collection(collection_id)print(f'Description: {collection["description"]}')print(f'License: {collection["license"]}')print(f'DOI: {collection["sci:doi"]}')print(f'Citation: {collection["sci:citation"]}')Description: LandCoverNet South America LabelsLicense: CC-BY-4.0DOI: doi.org/10.34911/rdnt.6a27yvCitation: Radiant Earth Foundation (2022) "LandCoverNet South America: A Geographically Diverse Land Cover Classification Training Dataset", Version 1.0, Radiant MLHub. https://doi.org/10.34911/rdnt.6a27yv
We download the zipped file in the labels directory. Then, we extract it there.
client.download_archive(collection_id, output_dir=’./labels’)!tar -xvzf ./labels/ref_landcovernet_sa_v1_labels.tar.gz -C ./labels/
The purpose of the next preprocessing steps is to adjust the format of the downloaded dataset to the directory structure required by the unetseg package. As a reminder, chips of images need to be in a directory called images, while the annotations need to be in the extent directory. Each chip must have the same name in each directory.
The fact that we do not use the satproc package here may be strange for those who have been reading our posts. But the reason behind this is that the data are in chip format. However, if it were necessary to change the chip size, satproc could be a good option to complete that step.
2- Preprocessing of Sentinel-2 imagery
This is the structure of each chip after downloading bands 2, 3 and 4:
!ls data/ref_landcovernet_sa_v1_source_sentinel_2_21MXR_18_20181231/labels21MXR_18_20181231_B02_10m.tif 21MXR_18_20181231_B04_10m.tif21MXR_18_20181231_B03_10m.tif
Based on the mentioned directory structure needed to train the model with unetseg, we need to rename each raster file with the name of the appropriate chip, in order to move them to the images directory later. Before that, we need to combine the three files linked to each band in one single file, using a virtual raster which we will delete later.
chips = glob.glob(‘./data/ref_landcovernet_sa_v1_source_sentinel_2*’)os.makedirs(‘./train/images’, exist_ok=True)for chip_dir in chips:chip_name_vrt = chip_dir.replace(‘./data/ref_landcovernet_sa_v1_source_sentinel_2_’,’’) + ‘.vrt’chip_name_tif = (‘_’).join(chip_dir.replace(‘./data/ref_landcovernet_sa_v1_source_sentinel_2_’,’’).split(‘_’)[:2])+ ‘.tif’print(chip_name_tif)outfile_vrt = os.path.join(‘train/images’, chip_name_vrt)outfile_tif = os.path.join(‘train/images’, chip_name_tif)inputs_path = os.path.join(chip_dir, ‘labels’, ‘*.tif’)!gdalbuildvrt -separate $outfile_vrt $inputs_path!gdal_translate $outfile_vrt $outfile_tif!rm $outfile_vrt
This is the resulting structure:
!ls images21LUE_25.tif 21MXR_15.tif 23LKC_00.tif 23LKC_20.tif 23LMJ_10.tif21LUE_26.tif 21MXR_16.tif 23LKC_01.tif 23LKC_21.tif 23LMJ_11.tif21LUE_27.tif 21MXR_17.tif 23LKC_02.tif 23LKC_22.tif 23LMJ_12.tif21LUE_28.tif 21MXR_18.tif 23LKC_03.tif 23LKC_23.tif 23LMJ_13.tif21LUE_29.tif 21MXR_19.tif 23LKC_04.tif 23LKC_24.tif 23LMJ_14.tif21MXR_00.tif 21MXR_20.tif 23LKC_05.tif 23LKC_25.tif 23LMJ_15.tif21MXR_01.tif 21MXR_21.tif 23LKC_06.tif 23LKC_26.tif 23LMJ_16.tif21MXR_02.tif 21MXR_22.tif 23LKC_07.tif 23LKC_27.tif 23LMJ_17.tif21MXR_03.tif 21MXR_23.tif 23LKC_08.tif 23LKC_28.tif 23LMJ_18.tif21MXR_04.tif 21MXR_24.tif 23LKC_09.tif 23LKC_29.tif 23LMJ_19.tif21MXR_05.tif 21MXR_25.tif 23LKC_10.tif 23LMJ_00.tif 23LMJ_20.tif21MXR_06.tif 21MXR_26.tif 23LKC_11.tif 23LMJ_01.tif 23LMJ_21.tif21MXR_07.tif 21MXR_27.tif 23LKC_12.tif 23LMJ_02.tif 23LMJ_22.tif21MXR_08.tif 21MXR_28.tif 23LKC_13.tif 23LMJ_03.tif 23LMJ_23.tif21MXR_09.tif 21MXR_29.tif 23LKC_14.tif 23LMJ_04.tif 23LMJ_24.tif21MXR_10.tif 22KEU_05.tif 23LKC_15.tif 23LMJ_05.tif 23LMJ_25.tif21MXR_11.tif 22KEU_07.tif 23LKC_16.tif 23LMJ_06.tif 23LMJ_26.tif21MXR_12.tif 22KEU_13.tif 23LKC_17.tif 23LMJ_07.tif 23LMJ_27.tif21MXR_13.tif 22KEU_21.tif 23LKC_18.tif 23LMJ_08.tif 23LMJ_28.tif21MXR_14.tif 22KEU_22.tif 23LKC_19.tif 23LMJ_09.tif 23LMJ_29.tif
3- Preprocessing of annotations
In this case, the structure of each chip is the following:
ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/labels.tifref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/source_dates.csvref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/stac.json
The raster file with the annotations is located in labels.tif. It is worth noting that the chips correspond to images from different dates. To simplify the analysis, in this post we will ignore that and consider every chip as if they had the same date. It is worth pointing out that the pixel value linked to the Cultivated Area class is 6 (we will use it with the command gdal_calc.py)
os.makedirs(‘extent’, exist_ok=True)chips = glob.glob(‘data/ref_landcovernet_sa_v1_labels/*/*.tif’)for chip_path in chips:chip_dir = os.path.dirname(chip_path)chip_name = chip_dir.replace(‘data/ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_’,’’)chip_name_tif = os.path.join(‘./train/extent’,chip_name + ‘.tif’)!gdal_calc.py -A $chip_path — outfile=$chip_name_tif — calc=”A==6" — NoDataValue=0
This is the resulting structure:
ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/ref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/labels.tifref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/source_dates.csvref_landcovernet_sa_v1_labels/ref_landcovernet_sa_v1_labels_21MXR_18/stac.json
Now that we have the files names and directories structured, we will continue with the configuration of the model training.
4- Model training
First, we need to install the unetseg python package. This package streamlines the training and prediction of deep learning models based on the U-Net architecture for semantic segmentation problems in relation with geospatial imagery.
!pip3 install unetsegfrom unetseg.train import TrainConfig, trainfrom unetseg.evaluate import plot_data_generator
Then, we configure the available parameters to instantiate the training. The documentation includes a list of the available parameters to train the models.
train_config = TrainConfig(width=256,height=256,n_channels=3,n_classes=1,apply_image_augmentation=True,seed=42,epochs=15,batch_size=4,steps_per_epoch=1,early_stopping_patience=3,validation_split=0.2,test_split = 0.1,model_architecture = “unet”,images_path=os.path.join(‘./model’),model_path=os.path.join(‘./model/weights/’, ‘UNet_test.h5’),evaluate=True)
As it can be observed, the chips size is 256x256 pixels, just as the chips included in the dataset. The number of classes is 1, just as it was indicated in the previous section. The model weights that we will use to predict the next step are stored in the model directory. The remaining parameters were selected at random to let the user experiment with them to achieve the best combination possible.
Let’s see an example of what the chips and the masks generated previously look like:
plot_data_generator(train_config=train_config, num_samples=1, fig_size=(10,5))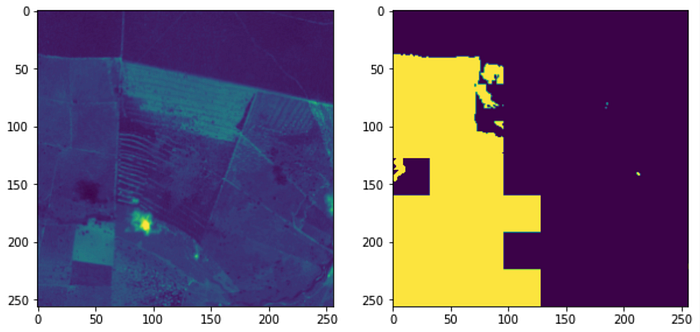
We train the model:
res_config = train(train_config)Once the model is trained, it can be used to predict new images. In the next post, we will explain this step in depth. You can check this tutorial if you are eager to continue with this step.
If you have any doubts or if you are interested in applying the code to your project or business, do not hesitate to contact us at contact@dymaxionlabs.com .
Notebook: https://colab.research.google.com/drive/1QweySv8JCw1hj89nxt0SnVaPG5HuHPGY?usp=sharing
*Radiant Earth Foundation (2022) “LandCoverNet South America: A Geographically Diverse Land Cover Classification Training Dataset”, Version 1.0, Radiant MLHub. [Date Accessed] https://doi.org/10.34911/rdnt.6a27yv
